RocksDB是什么
一、概述
1.1 简介
RocksDB 是一个持久、内嵌型 K/V存储引擎,键和值是任意大小的字节流(没有类型)。它支持point lookup和range scan,并提供不同类型的 ACID 保证。它是一个 C++ 库。RocksDB 借鉴了开源leveldb项目的重要代码以及Apache HBase的设计理念。初始代码是从开源 leveldb 1.5 fork而来的。它还以 Meta 在 RocksDB 之前开发的代码和理念为基础。
RocksDB 具有高度灵活的设置,可以根据不同的生产环境进行调优,包括 SSD、硬盘、ramfs 或远程存储。它支持多种压缩算法,并提供了良好的生产支持和调试工具。另一方面,RocksDB 也努力限制可调参数的数量,提供足够好的开箱即用性能,并在适用的地方使用一些自适应算法。
“内嵌” 意味着:
- 该数据库没有独立进程,而是被集成进应用中,和应用共享内存等资源,从而避免了跨进程通信的开销。
- 它没有内置服务器,无法通过网络进行远程访问。
- 它不是分布式的,这意味着它不提供容错性、冗余或分片(sharding)机制。
如有必要,需依赖于应用层来实现上述功能。
RocksDB 提供了很少的几个用于修改 kv 集合的函数底层接口:
put(key, value):插入新的键值对或更新已有键值对merge(key, value):将新值与给定键的原值进行合并delete(key):从集合中删除键值对
获取指定 key 所关联的 value:
get(key)
通过迭代器可以进行范围扫描 —— 找到特定的 key,并按顺序访问该 key 后续的键值对:
iterator.seek(key_prefix); iterator.value(); iterator.next()
1.2 高度分层架构
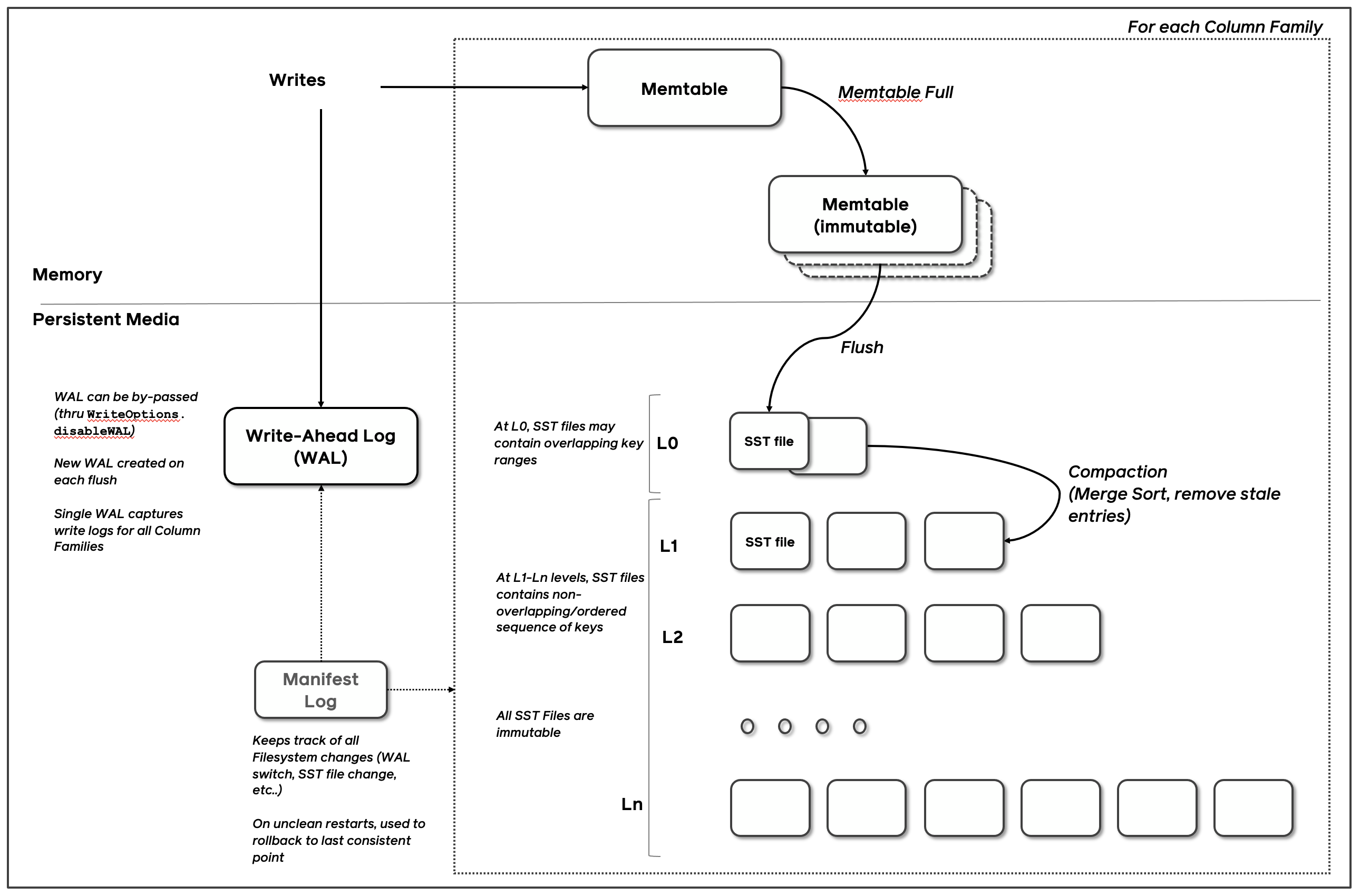
RocksDB 的核心数据结构被称为日志结构合并树 (LSM-Tree)。它是一种树形的数据结构,由多个层级组成,每层的数据按 key 有序。LSM-Tree 主要设计用来应对写入密集型工作负载,并于 1996 年在同名论文 The Log-Structured Merge-Tree (LSM-Tree) 被大家所知,其核心思想是充分利用了磁盘批量的顺序IO要远比随机IO性能好。
LSM-Tree 的最高层保存在内存中,包含最近写入的数据。其他较低层级的数据存储在磁盘上,层数编号从 0 到 N 。第 0 层 L0 存储从内存移动到磁盘上的数据,第 1 层及以下层级则存储更老的数据。通常某层的下个层级在数据量上会比该层大一个数量级,当某层数据量变得过大时,会合并到下一层。
1.2.1 MemTable
MemTable是一个内存数据结构,在键值对写入磁盘之前,Memtable 会缓存住这些键值对。所有插入和更新操作都会过 MemTable。当然也包括删除操作:不过,在 RocksDB 中,并不会直接原地修改键值对,而是通过插入墓碑记录(tombstone )来进行标记删除。
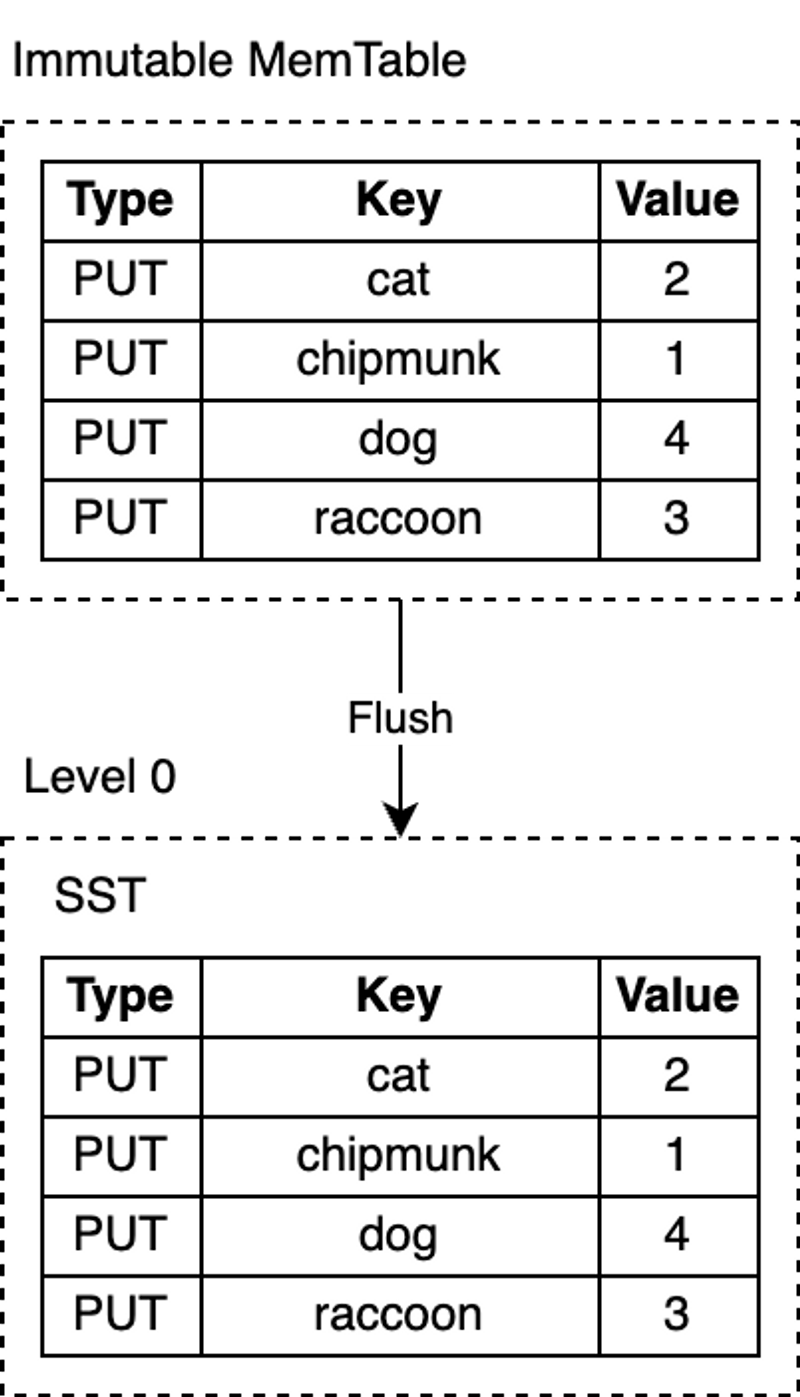
MemTable 具有可配置的字节数限制。当一个 MemTable 变满时,就会切到一个新的 MemTable。同时原 MemTable 变为不可修改状态,由后台线程把内容flush到一个SST文件,然后将该MemTable销毁。
例如现在向数据库中插入key
1 | db.put("chipmunk", "1") |
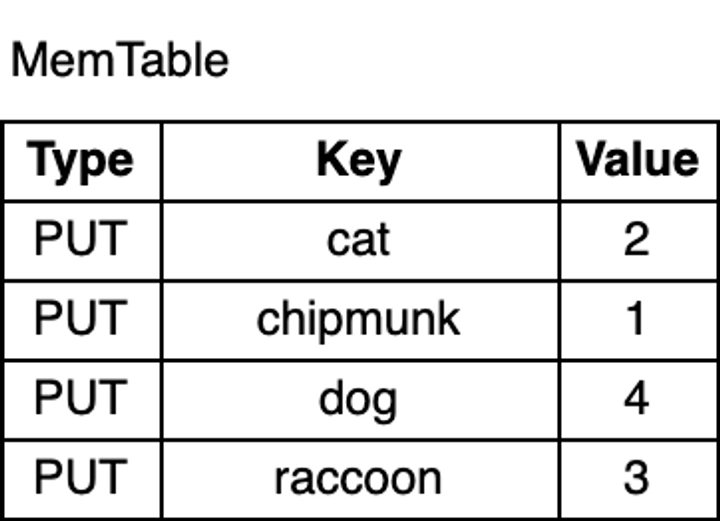
如上图所示,MemTable 中的键值对是按 key 有序排列的。尽管 chipmunk 是最先插入的,但由于 MemTable 是按 key 有序的,因此 chipmunk 排在 cat 之后。这种排序对于范围扫描是必须的。
影响memtable的最重要的几个选项是:
- memtable_factory: memtable对象的工厂。通过声明一个工厂对象,用户可以改变底层memtable的实现,并提供事先声明的选项。
- write_buffer_size:一个memtable的大小
- db_write_buffer_size:多个列族的memtable的大小总和。这可以用来管理memtable使用的总内存数。
- write_buffer_manager:除了声明memtable的总大小,用户还可以提供他们自己的写缓冲区管理器,用来控制总体的memtable使用量。这个选项会覆盖db_write_buffer_size
- max_write_buffer_number:内存中可以拥有刷盘到SST文件前的最大memtable数。
默认的MemTable实现是基于skiplist。用户也可以使用其他MemTable实现,例如HashLinkList,HashSkipList或者Vector,以满足不同场景需求。
| MEMTABLE类型 | SKIPLIST | HASHSKIPLIST | HASHLINKLIST | VECTOR |
|---|---|---|---|---|
| 最佳使用场景 | 通用 | 带特殊key前缀的范围查询 | 带特殊key前缀,并且每个前缀都只有很小数量的行 | 大量随机写压力 |
| 索引类型 | 二分搜索 | 哈希+二分搜索 | 哈希+线性搜索 | 线性搜索 |
| 是否支持全量db有序扫描 | 天然支持 | 非常耗费资源(拷贝以及排序一生成一个临时视图 | 同HashSkipList | 同HashSkipList |
| 额外内存 | 平均(每个节点有多个指针 | 高(哈希桶+非空桶的skiplist元数据+每个节点多个指针 | 稍低(哈希桶+每个节点的指针 | 低(vector尾部预分配的内存) |
| Memtable落盘 | 快速,以及固定数量的额外内存 | 慢,并且大量临时内存使用 | 同HashSkipList | 同HashSkipList |
| 并发插入 | 支持 | 不支持 | 不支持 | 不支持 |
| 带Hint插入 | 支持(在没有并发插入的时候 | 不支持 | 不支持 | 不支持 |
1.2.2 WAL
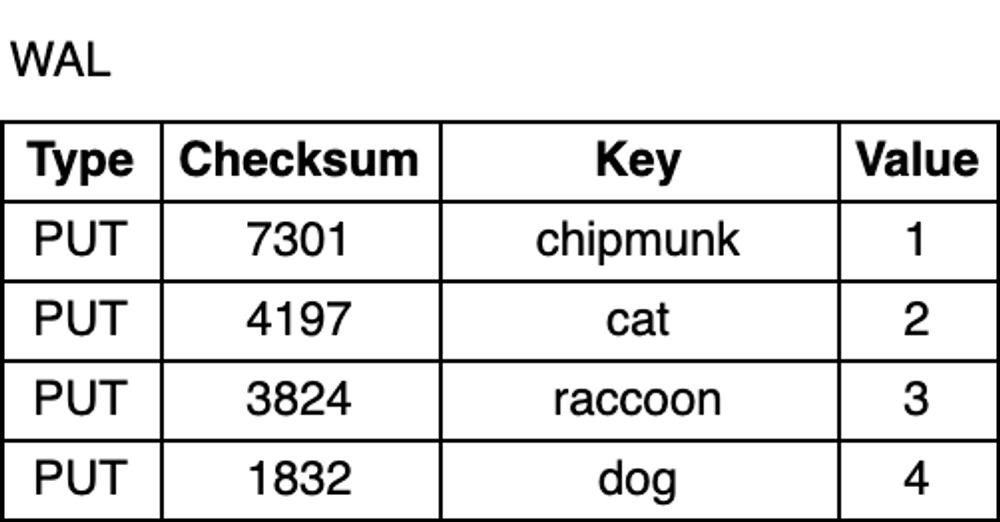
当进程崩溃或机器异常时,其内存数据都会丢失。为了防止数据丢失,保证数据的持久化,RocksDB 会将所有更新写入到磁盘上的预写日志(WAL,write-ahead log)中。当发生异常时,RocksDB可以回放日志,恢复数据。
WAL 是一个只允许追加的文件,包含一组更改记录序列。每个记录包含键值对、记录类型(Put / Merge / Delete)和校验和(checksum,可选)。与 MemTable 不同,在 WAL 中,记录不按 key 有序,而是按照请求到来的顺序被追加到 WAL 中。
1.2.3 SSTable
SSTable (Sorted String Table) 是一种持久化,有序且不可变的的键值存储结构。为了管理,RocksDB会将一个SST文件切分为若干个固定大小的block,每个block都有一个校验和用于检测数据是否损坏。每次从磁盘读取数据时,RocksDB 都会使用这些校验和进行校验。为了节省磁盘空间,RocksDB 提供了多种压缩算法,以平衡性能和压缩率。例如:Zlib、BZ2、Snappy(默认)、LZ4 或 ZSTD 算法。
尽管 SST 中的 kv 对是有序的,我们也并非总能进行二分查找,尤其是数据块在压缩过后,会使得查找很低效。RocksDB 使用索引来优化查询,索引存储在紧邻数据块之后。索引块会存储每个 block 中最后一个 key与该key在SST文件中偏移量的映射关系,并且索引块中 key 也是有序的,因此我们可以通过二分搜索快速找到某个 key。
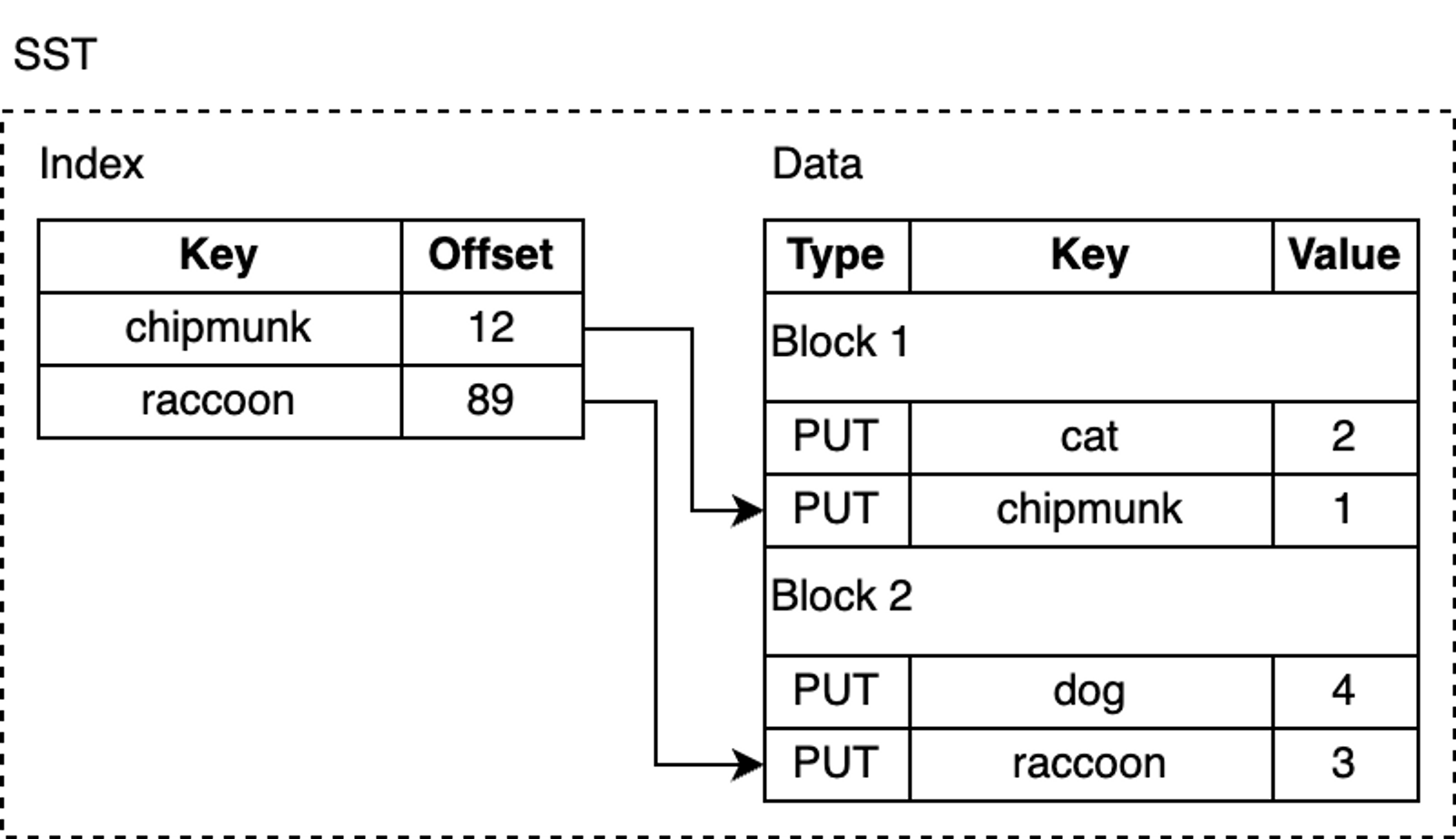
例如,我们在查找 lynx,索引会告诉我们这个键值对可能在 block 2,因为按照字典序,lynx 在 chipmunk 之后,但在 raccoon 之前。但其实 SST 文件中并没有 lynx,但我们仍然需要从磁盘加载 block 以进行搜索。RocksDB 支持启用布隆过滤器,一种具有高效空间利用率的概率性数据结构,可以用来检测某个元素是否在集合中。布隆过滤器保存在 SST 文件中过滤器部分,以便能够快速确定某个 key 不在 SST 中,减少无效磁盘访问,极大提升了查询速度。
Flush
RocksDB 使用一个专门的后台线程定期地把不可变的MemTable从内存持久化到磁盘。一旦刷盘(flush)完成,不可变的MemTable 和相应的 WAL 就会被丢弃。RocksDB 开始写入新的 WAL、MemTable。每次刷盘都会在 L0 层上产生一个新的 SST 文件。该文件一旦写入磁盘后,就不再会修改。
RocksDB 的 MemTable 的默认基于跳表实现。该数据结构是一个具有额外采样层的链表,从而允许快速、有序地查询和插入数据。有序性使得 MemTable 刷盘时更高效,因为可以直接按顺序迭代键值对顺序写入磁盘。将随机写变为顺序写是 LSM-Tree 的核心设计之一。
Compaction
当低level的SST文件数量或者大小达到阈值时,会进行Compaction。之所以进行Compaction是因为如果所有SST文件位于L0层会有空间放大(space amplifications)和读放大(read amplifications)的问题。
空间放大是存储数据所用实际空间与逻辑上数据大小的比值。假设一个数据库需要 2 MB 磁盘空间来存储逻辑上的 1 MB 大小的键值对是,那么它的空间放大率是 2。类似地,读放大用来衡量用户执行一次逻辑上的读操作,系统内所需进行的实际 IO 次数。
现在,让我们向数据库添加更多 key 并删除当中的一些 key:
1 | db.delete("chipmunk") |
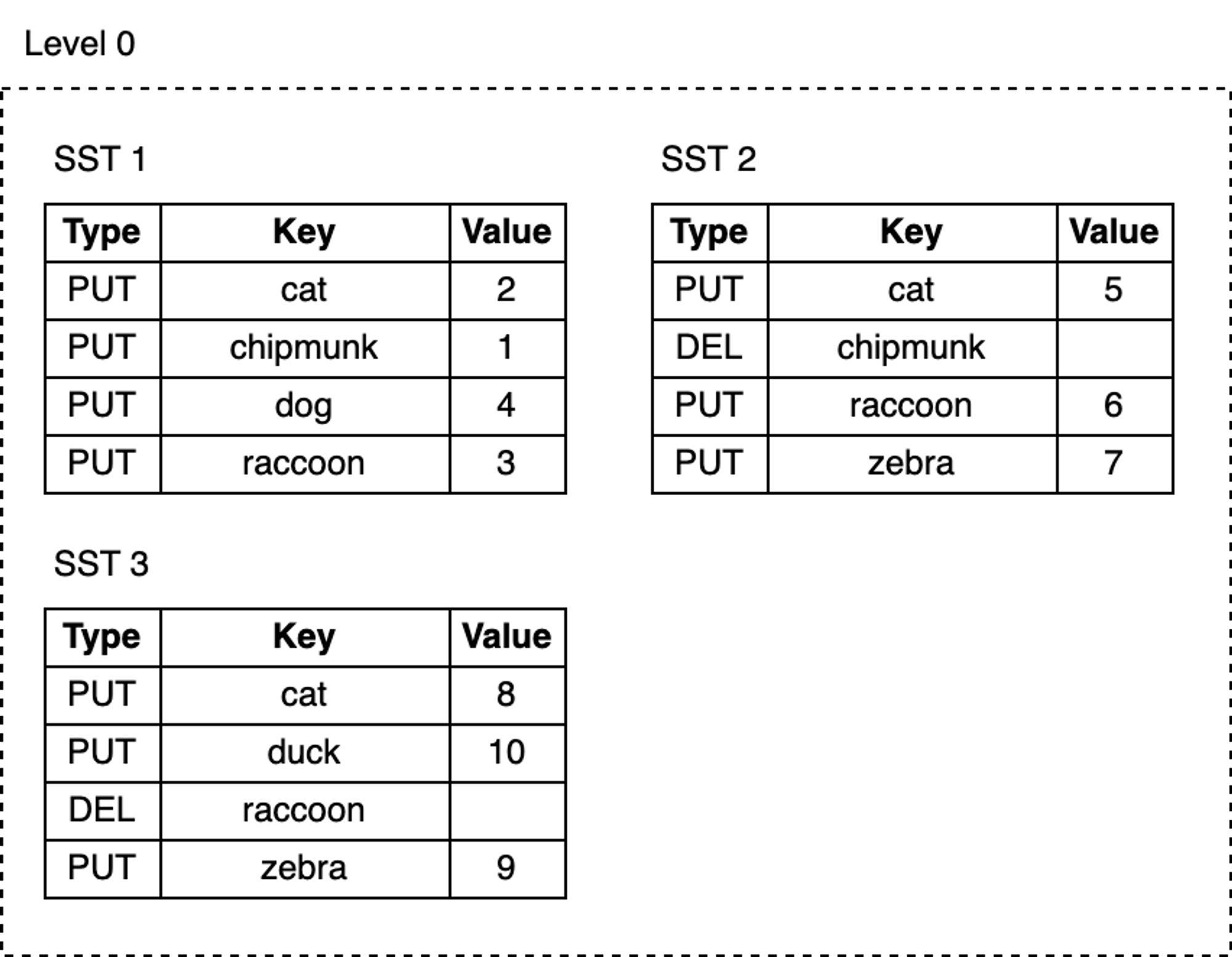
随着我们的不断写入,MemTable 不断被刷到磁盘,L0 上的 SST 文件数量也在增长:
- 删除或更新 key 所占用的空间永远不会被回收。例如,
cat这个 key 的三次更新记录分别在 SST1,SST2 和 SST3 中,而chipmunk在 SST1 中有一次更新记录,在 SST2 中有一次删除记录,这些无用的记录仍然占用额外磁盘空间。 - 随着 L0 上 SST 文件数量的增加,读取变得越来越慢。每次查找都要逐个检查所有 SST 文件。
RocksDB 引入了Compaction 机制,可以降低空间放大和读放大,但代价是更高的写放大。Compaction 会将某层的 SST 文件同下一层的 SST 文件合并,并在这个过程中丢弃已删除和被覆盖的无效 key。Compaction 会在后台专用的线程池中运行,从而保证了 RocksDB 可以在做 Compaction 时能够正常处理用户的读写请求。
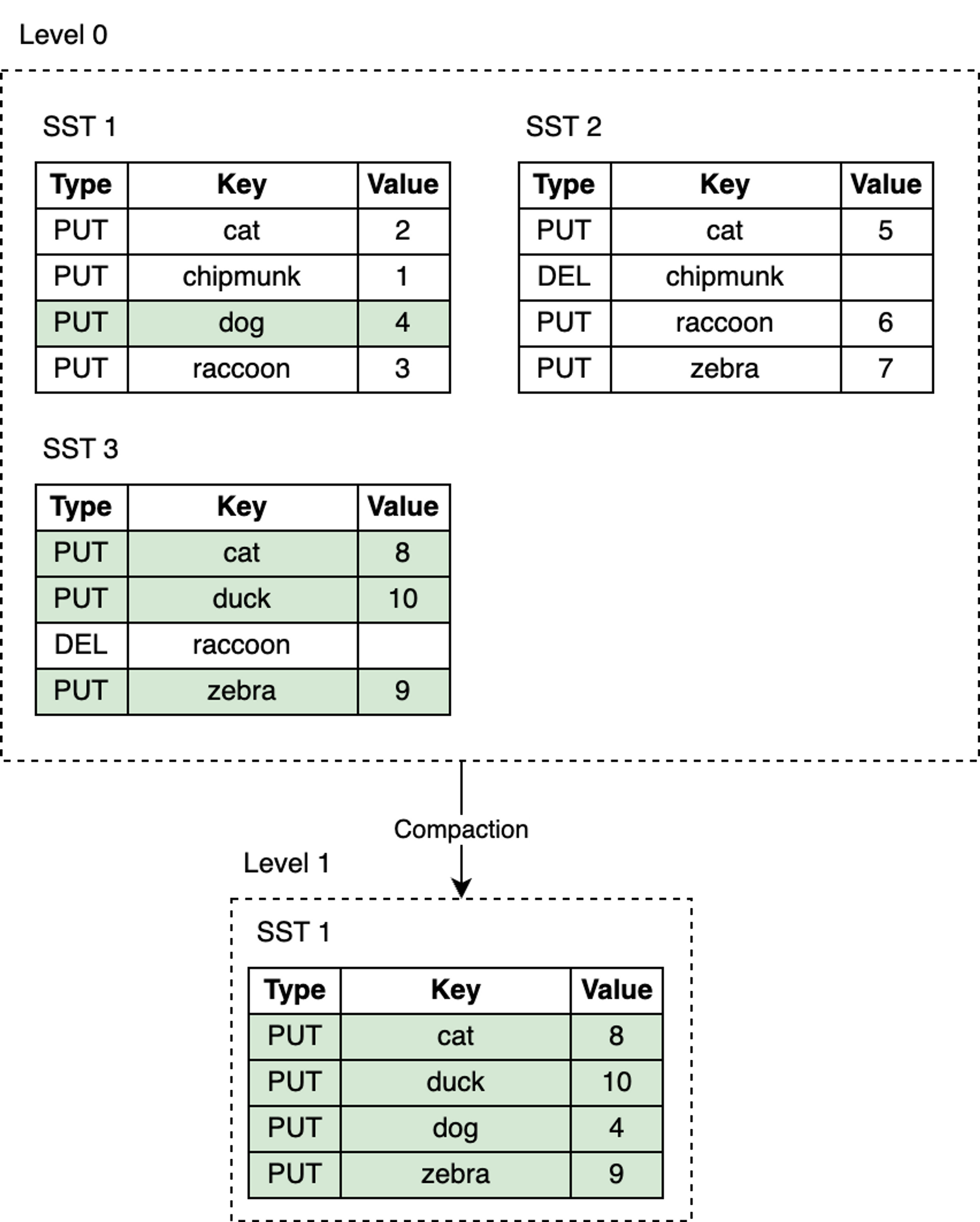
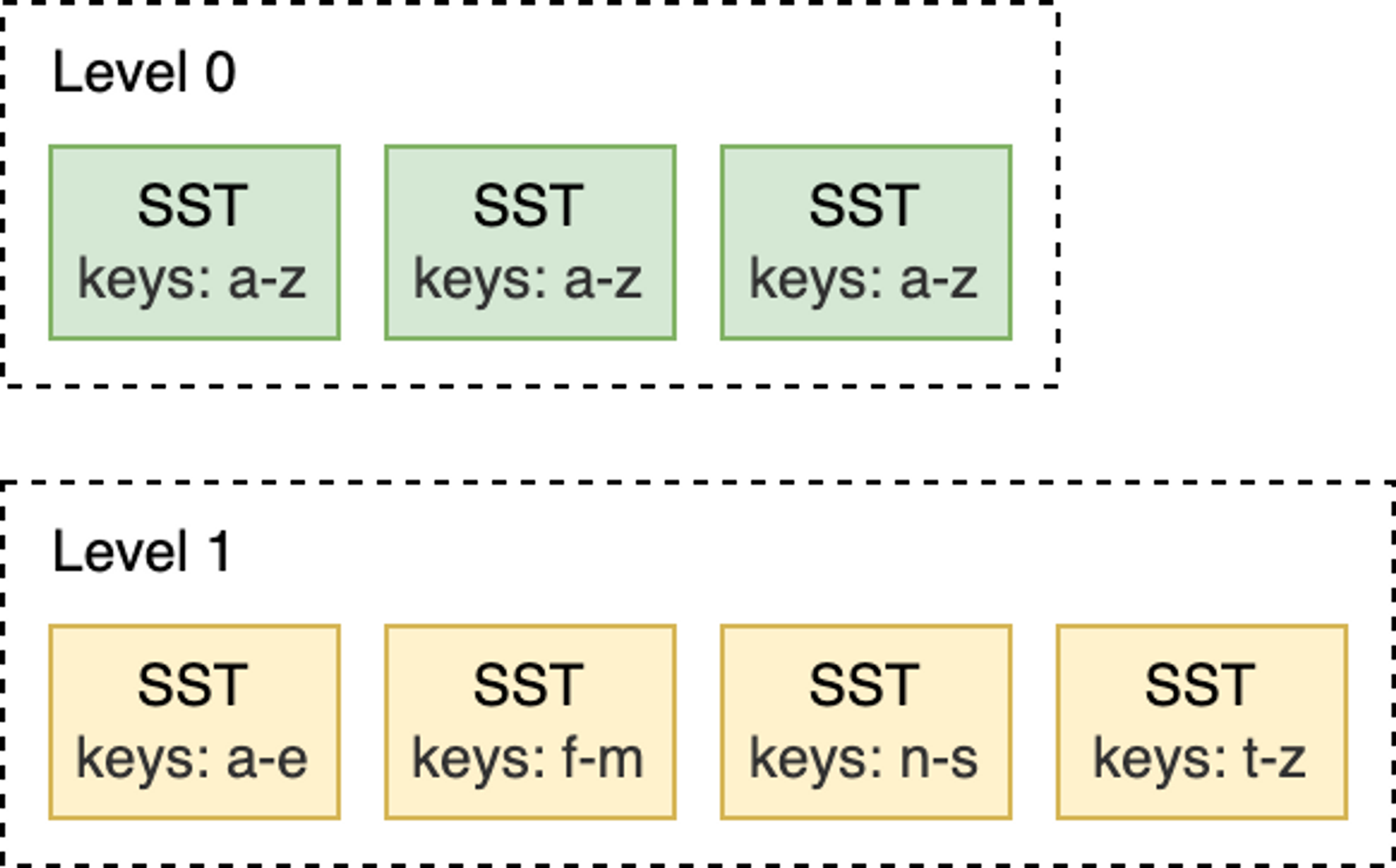
Level Style Compaction是 RocksDB 中的默认 Compaction 策略。使用 Level Style Compaction,L0 层中的不同SST 文件键范围会重叠。L1 层及以下层会被组织为包含多个 SST 文件的序列,并保证同层级内的所有 SST 在键范围上没有交叠,且 SST 文件之间有序。Compaction 时,会选择性地将某层的 SST 文件与下一层的 key 范围有重叠 SST 文件进行合并。
举例来说,如下图所示,在 L0 到 L1 层进行 Compaction 时,如果 L0 上的输入文件覆盖整个键范围,此时就需要对所有 L0 和 L1 层的文件进行 Compaction。
而像是下面的这种 L1 和 L2 层的 Compaction,L1 层的输入文件只与 L2 层的两个 SST 文件重叠,因此,只需要对部分文件进行 Compaction 即可。
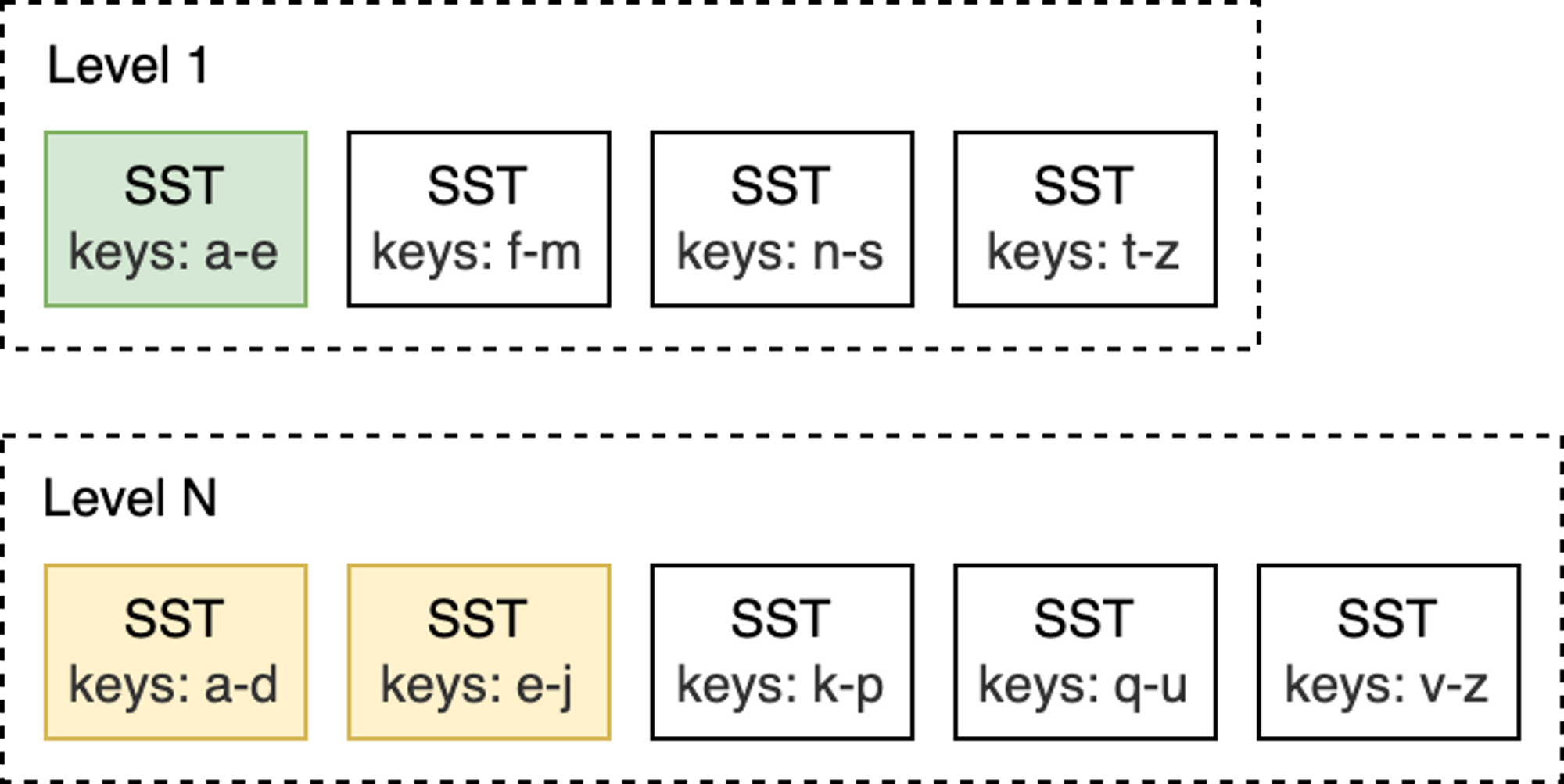
当 L0 层上的 SST 文件数量达到一定阈值(默认为 4)时,将触发 Compaction。对于 L1 层及以下层级,当整个层级的 SST 文件总大小超过配置的目标大小时,会触发 Compaction 。当这种情况发生时,可能会触发 L1 到 L2 层的 Compaction。从而,从 L0 到 L1 层的 Compaction 可能会引发一直到最底层级联 Compaction。在 Compaction 完成之后,RocksDB 会更新元数据并从磁盘中删除已经被 Compcated 过的文件。
注:RocksDB 提供了不同 Compaction 策略来在空间、读放大和写放大之间进行权衡。
1.2.4 写路径
1,(可选) 当收到一个写请求时,会先把该条数据append方式写到WAL文件,用作故障恢复。
2,当写完WAL后,会把该条数据写入内存的MemTable,随即返回写成功。
3,当Memtable超过一定的大小后,会在内存里面冻结,变成不可变的MemTable,同时为了不阻塞写操作生成一个新MemTable。
4,有后台线程把内存里不可变的Memtable给flush到磁盘,生成L0 SST文件。
5,从 L0 到 L1 层的 Compaction 可能会引发一直到最底层级联 Compaction。在 Compaction 完成之后,RocksDB 会更新元数据并从磁盘中删除已经被 Compcated 过的SST文件。
1.2.5 读路径
- 检索 MemTable。
- 检索所有不可变 MemTable。
- 搜索最近 flush 过的 L0 层中的所有 SST 文件。
- 对于 L1 层及以下层级,首先找到可能包含该 key 的单个 SST 文件,然后在文件内进行搜索。
搜索 SST 文件涉及:
- (可选)探测布隆过滤器。
- 查找 index 来找到可能包含这个 key 的 block 所在位置。
- 读取 block 文件并尝试在其中找到 key。
1.3 概述
列族(Column Families)
RocksDB支持将一个数据库实例按照许多列族进行分片。所有数据库创建的时候都会有一个用”default”命名的列族,如果某个操作不指定列族,他将操作这个default列族。不同的列族共享WAL,独享SST和MemTable,所以Column Family起到了一定的逻辑和资源隔离的作用。
RocksDB在开启WAL的时候保证即使crash,列族的数据也能保持一致性。它还通过 API 支持跨列族的原子操作WriteBatch。
Updates
APIPut将单个键值插入数据库。如果数据库中已存在该键,则将覆盖先前的值。APIWrite允许在数据库中原子地插入、更新或删除多个键值。数据库保证一次Write调用中的所有键值都将插入数据库,或者一个键值也不会插入数据库。如果数据库中已存在任何这些键,则将覆盖先前的值。APIDeleteRange可用于删除某个范围内的所有键。
Gets,Iterators and Snapshots
键和值被视为纯字节流。键或值的大小没有限制。GetAPI 允许应用程序从数据库中提取单个键值。MultiGetAPI 允许应用程序从数据库检索一组键。使用MultiGet获取的多个键值对将保证在同一时间点的一致性。
数据库中的所有数据都按逻辑顺序排列。应用程序可以定义一种键比较方法,用来指定键的排序规则。Iterator API允许对数据库做range scan 。Iterator可以查找指定的键,然后可以从该点开始一次扫描一个键。。Iterator API还可以用于对数据库中的键进行反向迭代。在创建Iterator时会创建数据库的一致时间点视图,因此,通过Iterator返回的所有键都来自数据库的一致视图。
SnapshotAPI允许应用程序创建数据库的时间点视图。Get和IteratorAPI 可用于从指定的snapshot读取数据。Snapshot和 Iterator都提供了数据库的时间点视图,但它们的实现不同。短期/前台扫描最好通过迭代器完成,而长时间/后台扫描最好通过快照完成。 Iterator会对整个指定时间点的数据库相关文件保留一个引用计数,这些文件在iterator释放前,都不会被删除。另一方面,snapshot不会阻止文件删除;相反,compaction过程知道snapshot存在,并承诺永远不会删除在任何现有快照中可见的key。
Snapshot在数据库重启后不会保留:reload RocksDB库会释放所有之前创建好的snapshot。
事务(transaction)
RocksDB支持多操作事务。它支持乐观模式和悲观模式。参考 事务。
前缀迭代器(Prefix Iterators)
大多数 LSM-tree 引擎无法支持高效的range scan API,因为它需要查看多个数据文件。但是,大多数应用程序不会对数据库中的键进行纯随机范围扫描;相反,应用程序通常只扫描指定前缀的键。RocksDB 利用了这一点。应用程序可以配置Options.prefix_extractor以启用基于键前缀的过滤。启用后,会将前缀的hash添加到布隆过滤器(Bloom Filter)中。指定了键前缀的Iterator(在ReadOptions中)将使用布隆过滤器来避免查找不包含指定键前缀的数据文件。参阅前缀查找。
持久性(Persistence)
RocksDB 有一个预写日志 (WAL)。所有写入操作(Put、Delete和Merge)都存储在名为 memtable 的内存缓冲区中,也可以选择性地写入 WAL。重新启动时,它会重新处理日志中记录的所有事务。
WAL 可以配置为存储在与 SST 文件 不同的目录中。这对于您可能希望将所有数据文件存储在非持久性快速存储中的情况是必要的。同时,您可以通过将所有事务日志放在较慢但持久的存储上来确保不会丢失数据。
每次Put都有一个标志位,通过WriteOptions来设置,允许指定这个Put操作是不是需要写事务日志。WriteOptions同时允许指定在Put返回成功前,是不是需要调用fsync。
在内部,RocksDB 使用批量提交机制将事务批量放入日志中,以便它可以使用单个fsync调用提交多个事务。
数据校验
RocksDB 使用校验和来检测存储中的损坏。每个 SST 文件块(通常大小在 4KB 到 128KB 之间)都会有一个单独的校验和。块一旦写入存储,就不再做修改。RocksDB 还维护完整的文件校验和(请参阅完整文件校验和和校验和切换)以及可选的每个键值校验和。
RocksDB 动态检测并利用 CPU 校验和卸载支持。
Multi-Threaded Compactions
在存在持续写入的情况下,需要进行compactions以提高空间效率、读取(查询)效率和及时删除数据。Compaction会删除已删除或覆盖的键值,并重新组织数据以提高查询效率。如果配置的话,Compactions 可能会在多个线程中同时进行。
整个数据库存储在一组SST文件中。当memtable写满时,其内容将写入 LSM-tree的 Level-0 (L0) 文件中。RocksDB 在将memtable 刷新到 L0 文件中时,会删除重复和覆盖的键。在compaction中,一些文件会定期读入并合并以形成更大的文件,通常会进入下一个 LSM 级别(例如 L1,直到 Lmax)。
LSM 数据库的整体写入吞吐量直接取决于compaction发生的速度,尤其是当数据存储在 SSD 或 RAM 等快速存储中时。RocksDB 可以配置为从多个线程发出并发compaction请求。据观察,当数据库位于 SSD 上时,与单线程compaction相比,多线程compaction可以将持续写入速率提高10倍。
Compaction Styles
Level Style Compaction和Universal Style Compaction都将数据存储在数据库中固定数量的逻辑级别中。较新的数据存储在级别 0 (L0) 中,较旧的数据存储在编号较高的级别中,最高可达 Lmax。L0中的文件可能会有重叠的键,但其他级别的文件通常会在每个级别上单独排序。
Level Style Compaction(默认)通常通过最小化每个Compaction步骤中涉及的文件来优化磁盘占用空间与逻辑数据库大小(空间放大):将 Ln 中的一个文件与 Ln+1 中的所有重叠文件合并,并用 Ln+1 中的新文件替换它们。
Universal Style Compaction通常通过一次合并多个文件和级别来优化写入磁盘的总字节数与逻辑数据库大小(写入放大),从而需要更多临时空间。与Level Style Compaction相比,Universal Style Compaction通常会导致写放大更低,但空间和读放大更高。
FIFO Style Compaction会删除过时的旧文件,并可用于类似缓存的数据。在FIFO compaction中,所有文件都在L0级。当数据的总大小超过配置的大小(CompactionOptionsFIFO::max_table_files_size)时,我们删除最旧的SST文件。
我们还允许开发人员开发和测试自定义compaction策略。为此,RocksDB有适当的钩子来关闭内建的compaction算法,然后使用其他API来允许应用使用他们自己的compaction算法。Options.disable_auto_compaction如果设置,则关闭内建的compaction算法。GetLiveFilesMetaData API允许外部组件查看数据库中的每个数据文件,并决定要merge和compaction哪些数据文件。调用CompactFiles以compaction您想要的文件。该DeleteFileAPI 允许应用程序删除被视为过时的数据文件。
元数据存储
清单日志文件用于记录数据库所有状态变化。compaction过程中会在数据库中添加新文件和删除原有文件,并通过将这些操作记录在MANIFEST中来使这些操作持久化。
Avoiding Stalls
后台compaction线程还用于将memable的内容flush到存储上的文件中。如果所有后台compaction线程都长时间忙于compaction,突发性的写操作可能很快填满memable,从而阻塞新的写入。可以通过配置 RocksDB 来保留一小组线程,专门用于将memable flush到存储,从而避免这种情况。
Compaction Filter
某些应用程序可能希望在compaction时处理键,例如根据 TTL 删除过期的键、在后台删除一定范围的键、更新现有键的值。这可以通过应用程序定义的Compaction Filter来完成。
只读模式
数据库可以以只读模式打开,在该模式下,数据库保证应用程序无法修改任何数据。这大大提高了读取性能,因为避免了一些锁机制。
数据库调试日志
默认情况下,RocksDB将详细日志写入名为LOG*的文件。这些日志主要用于调试和分析正在运行的系统。用户可以选择不同的日志级别(参见 DBOptions.info_log_level)。日志文件可以配置为按照指定的周期进行滚动。日志接口是可插拔的,用户可以选择使用不同的记录器,参考记录器。
Data Compression
RocksDB 支持 lz4、zstd、snappy、zlib 和 lz4_hc压缩,以及 Windows 下的 xpress。RocksDB可以为不同level的SST文件配置不同的压缩算法。请参阅压缩。
全量备份与复制
RocksDB 提供了BackupEngine API进行备份,可参考How to backup RocksDB。
RocksDB 本身不是复制的,但它提供了一些辅助函数,使用户能够在 RocksDB 之上实现自己的复制系统,可参考 Replication Helpers。
支持同一个进程打开多个数据库
RocksDB 的一个常见用法是应用程序将数据集划分为逻辑分区或分片。此技术有利于应用程序负载均衡以及快速故障恢复。这意味着单个进程应能同时操作多个RocksDB数据库。这是通过一个名为Env的对象完成的。除此之外,线程池与Env相关联,如果想在多个数据库实例之间共享一个公共线程池(用于后台compaction),那么它应该使用同一个Env对象来打开这些数据库。
类似地,多个数据库实例可以共享相同的块缓存或速率限制器。
Block Cache
RocksDB对block使用LRU做读缓存。 block cache分为两个单独的cache:第一个缓存未压缩的block,第二个缓存在内存中压缩的block。如果配置了压缩block缓存,用户可能希望启用direct I/O ,以防止在操作系统的页缓存中缓存相同的数据。
Table Cache
Table Cache是缓存打开的文件描述符的结构。这些文件描述符用于sstfiles。应用程序可以指定Table Cache的最大大小,或将 RocksDB 配置为始终保持所有文件打开状态,以提高性能。
I/O Control
RocksDB允许用户以不同的方式配置从SST文件或到SST文件的I/O。用户可以启用direct I/O,以便RocksDB完全控制I/O和缓存。另一种方法是利用一些选项允许用户提示应该如何执行I/O。他们可以建议RocksDB在读取文件时调用 fadvise,在正在追加数据的文件中定期调用 range sync。有关更多详细信息,请参阅IO。https://github.com/johnzeng/rocksdb-doc-cn/blob/master/doc)
StackableDB
RocksDB 具有内置的包装器机制,可以在数据库核心代码之上添加额外的功能,这些功能通过StackableDBAPI封装。例如,TTL功能是由StackableDB接口实现的,并不是RocksDB核心API的一部分,这种方法使代码保持模块化和干净。
Merge Operator
RocksDB 原生支持三种类型的记录,即Put、Delete、Merge记录。当compaction过程遇到Merge时,它会调用应用程序指定的方法,称为合并运算符。合并可以将多个 Put 和 Merge 记录合并为一条记录。这个强大的功能允许通常执行读取-修改-写入的应用程序完全避免读取。它允许应用程序将操作意图记录为Merge记录,而 RocksDB compaction过程会将该意图延迟应用于原始值。此功能在合并运算符中有详细描述
DB ID
数据库创建时创建的全局唯一ID,默认存储在 DB 文件夹中的 IDENTITY文件中。可选地,它只存储在MANIFEST文件中。建议存储在 MANIFEST 文件中。
1.4 工具
有许多有趣的工具用于支持生产环境中的数据库。sst_dump程序转储sst文件中的所有键值,以及其他信息。ldb工具可以put, get,s can数据库的内容。ldb还可以转储MANIFEST的内容,它还可以用来修改数据库配置的层级数。有关详细信息,请参阅管理和数据访问工具。
1.5 LevelDB 所没有的特性
Performance:
- Multithread compaction
- Multithread memtable inserts
- Reduced DB mutex holding
- Optimized level-based compaction style and universal compaction style
- Prefix bloom filter
- Memtable bloom filter
- Single bloom filter covering the whole SST file
- Write lock optimization
- Improved Iter::Prev() performance
- Fewer comparator calls during SkipList searches
- Allocate memtable memory using huge page.
Features:
- Column Families
- Transactions and WriteBatchWithIndex
- Backup and Checkpoints
- Merge Operators
- Compaction Filters
- RocksDB Java
- Manual Compactions Run in Parallel with Automatic Compactions
- Persistent Cache
- Bulk loading
- Forward Iterators/ Tailing iterator
- Single delete
- Delete files in range
- Pin iterator key/value
Alternative Data Structures And Formats:
- Plain Table format for memory-only use cases
- Vector-based and hash-based memtable format
- Clock-based cache (coming soon)
- Pluggable information log
- Annotate transaction log write with blob (for replication)
Tunability:
- Rate limiting
- Tunable Slowdown and Stop threshold
- Option to keep all files open
- Option to keep all index and bloom filter blocks in block cache
- Multiple WAL recovery modes
- Fadvise hints for readahead and to avoid caching in OS page cache
- Option to pin indexes and bloom filters of L0 files in memory
- More Compression Types: zlib, lz4, zstd
- Compression Dictionary
- Checksum Type: xxhash
- Different level size multiplier and compression type for each level.
Manageability:
- Statistics
- Thread-local profiling
- More commands in command-line tools
- User-defined table properties
- Event listeners
- More DB Properties
- Dynamic option changes
- Get options from a string or map
- Persistent options to option files
参考
RocksDB Wiki
RocksDB运行原理
深入理解什么是LSM-Tree